Druid 引領(lǐng)實(shí)時(shí)數(shù)據(jù)分析的新一代存儲與計(jì)算引擎
在大數(shù)據(jù)時(shí)代,數(shù)據(jù)的價(jià)值往往與處理速度直接相關(guān)。傳統(tǒng)的批處理系統(tǒng)雖然能夠處理海量數(shù)據(jù),但其固有的延遲無法滿足實(shí)時(shí)監(jiān)控、交互式查詢和即時(shí)決策等場景的迫切需求。在此背景下,Apache Druid應(yīng)運(yùn)而生,它作為一個(gè)開源的、分布式的、面向列的數(shù)據(jù)存儲系統(tǒng),專門為需要實(shí)時(shí)數(shù)據(jù)攝取、低延遲查詢和高可用性的應(yīng)用場景而設(shè)計(jì)。本文將深入解析Druid作為實(shí)時(shí)數(shù)據(jù)分析存儲系統(tǒng)的核心數(shù)據(jù)處理與存儲支持服務(wù)。
一、核心定位:為實(shí)時(shí)分析而生
Druid的設(shè)計(jì)哲學(xué)是融合數(shù)據(jù)倉庫、時(shí)間序列數(shù)據(jù)庫和搜索系統(tǒng)的優(yōu)勢。它不是一個(gè)通用的OLTP數(shù)據(jù)庫,而是專注于OLAP(在線分析處理)場景,特別是那些需要亞秒級查詢響應(yīng)的實(shí)時(shí)數(shù)據(jù)分析。無論是網(wǎng)站點(diǎn)擊流分析、廣告技術(shù)平臺、網(wǎng)絡(luò)性能監(jiān)控,還是物聯(lián)網(wǎng)傳感器數(shù)據(jù)分析,Druid都能提供強(qiáng)大的支持。
二、數(shù)據(jù)處理能力:實(shí)時(shí)與批處理的無縫融合
Druid的數(shù)據(jù)處理架構(gòu)是其強(qiáng)大能力的基石,主要體現(xiàn)在數(shù)據(jù)攝取和查詢處理兩個(gè)層面。
1. 實(shí)時(shí)數(shù)據(jù)攝取(流式攝入):
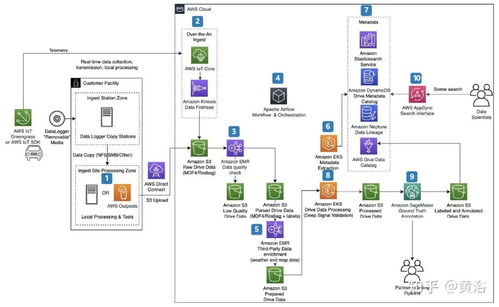
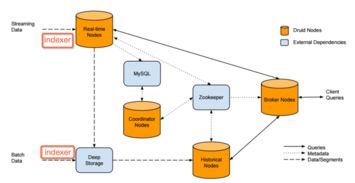
Druid能夠直接從消息隊(duì)列(如Kafka、Kinesis)中持續(xù)攝取數(shù)據(jù)流,實(shí)現(xiàn)近乎實(shí)時(shí)的數(shù)據(jù)可見性。其“實(shí)時(shí)節(jié)點(diǎn)”負(fù)責(zé)消費(fèi)流數(shù)據(jù),并構(gòu)建成內(nèi)存中的索引片段,隨后定期將這些片段持久化到深度存儲中,并移交歷史節(jié)點(diǎn)管理。這個(gè)過程確保了數(shù)據(jù)從產(chǎn)生到可查詢的延遲極低。
2. 批處理數(shù)據(jù)攝取:
對于存儲在HDFS、亞馬遜S3等數(shù)據(jù)湖中的歷史數(shù)據(jù)或批量數(shù)據(jù),Druid同樣支持高效地批量導(dǎo)入。這實(shí)現(xiàn)了實(shí)時(shí)流數(shù)據(jù)與歷史批數(shù)據(jù)的統(tǒng)一存儲和查詢,用戶可以用同一種查詢語言分析所有數(shù)據(jù)。
3. 查詢處理:
Druid使用基于JSON的查詢語言,并支持SQL(通過內(nèi)置的Avatica JDBC驅(qū)動或?qū)iT的SQL層)。其查詢引擎專為快速聚合和掃描優(yōu)化。當(dāng)查詢到達(dá)時(shí),協(xié)調(diào)節(jié)點(diǎn)會將查詢路由到相關(guān)的數(shù)據(jù)節(jié)點(diǎn)(歷史節(jié)點(diǎn)和實(shí)時(shí)節(jié)點(diǎn)),各節(jié)點(diǎn)并行處理本地?cái)?shù)據(jù)(利用列式存儲和位圖索引進(jìn)行快速過濾和聚合),中間結(jié)果再由代理節(jié)點(diǎn)或查詢節(jié)點(diǎn)匯總返回給用戶,整個(gè)過程通常在毫秒到秒級完成。
三、存儲支持服務(wù):為高性能查詢設(shè)計(jì)的架構(gòu)
Druid的存儲架構(gòu)是其實(shí)現(xiàn)低延遲查詢和高吞吐量的關(guān)鍵。
1. 列式存儲:
Druid按列存儲數(shù)據(jù)。這種格式對于分析型查詢極其高效,因?yàn)椴樵兺ǔV簧婕安糠至小V恍枳x取查詢所需的列,極大地減少了磁盤I/O,提高了掃描和聚合速度。
2. 分布式架構(gòu)與數(shù)據(jù)分片:
Druid是分布式系統(tǒng),數(shù)據(jù)被自動分割成多個(gè)“段”。每個(gè)“段”是一個(gè)獨(dú)立的數(shù)據(jù)單元,包含了某個(gè)時(shí)間區(qū)間內(nèi)的數(shù)據(jù),并進(jìn)行了壓縮和索引。這些段被分散在集群的歷史節(jié)點(diǎn)上,實(shí)現(xiàn)了數(shù)據(jù)的分布式存儲和并行處理能力。
- 多層索引結(jié)構(gòu):
- 位圖索引: 對于維度列,Druid會創(chuàng)建位圖索引,可以極其快速地進(jìn)行等值過濾和分組操作。
- 倒排索引: 支持高效的搜索式查詢。
- 時(shí)間索引: 數(shù)據(jù)默認(rèn)按時(shí)間分區(qū),查詢可以快速定位到特定時(shí)間范圍的段,這是時(shí)間序列分析的天然優(yōu)化。
- 壓縮編碼: 根據(jù)列的數(shù)據(jù)類型(如字符串、數(shù)值)應(yīng)用不同的壓縮算法(如字典編碼、游程編碼),減少存儲空間和內(nèi)存占用。
4. 深度存儲與容錯(cuò)性:
Druid采用存儲與計(jì)算分離的設(shè)計(jì)。處理好的數(shù)據(jù)“段”會持久化到一個(gè)共享的、高可用的“深度存儲”系統(tǒng)中(如S3、HDFS、Azure Blob)。計(jì)算節(jié)點(diǎn)(歷史節(jié)點(diǎn))從深度存儲加載段到本地進(jìn)行查詢服務(wù)。這種設(shè)計(jì)使得計(jì)算節(jié)點(diǎn)可以無狀態(tài)地?cái)U(kuò)展和故障恢復(fù):如果一個(gè)歷史節(jié)點(diǎn)宕機(jī),協(xié)調(diào)節(jié)點(diǎn)可以指揮另一個(gè)節(jié)點(diǎn)從深度存儲重新加載其負(fù)責(zé)的段,從而保證了系統(tǒng)的高可用性。
5. 預(yù)聚合(Roll-up):
在數(shù)據(jù)攝取階段,Druid支持可選的數(shù)據(jù)預(yù)聚合。它可以在攝入時(shí)根據(jù)指定的維度集合對數(shù)據(jù)進(jìn)行匯總,丟棄原始數(shù)據(jù),只保留聚合后的結(jié)果。這能顯著減少數(shù)據(jù)存儲量,并極大提升對固定維度組合的查詢性能,是應(yīng)對超大規(guī)模數(shù)據(jù)集的利器。
四、生態(tài)系統(tǒng)與集成
Druid擁有活躍的生態(tài)系統(tǒng),可以輕松與主流的大數(shù)據(jù)工具集成。它支持從Kafka、Flume、Spark、Flink等系統(tǒng)攝入數(shù)據(jù);可以通過Grafana、Superset、Tableau等可視化工具進(jìn)行數(shù)據(jù)展示;其SQL接口也使其易于被熟悉傳統(tǒng)數(shù)據(jù)庫的分析師使用。
###
Apache Druid通過其獨(dú)特的數(shù)據(jù)處理和存儲架構(gòu),在實(shí)時(shí)數(shù)據(jù)分析領(lǐng)域占據(jù)了重要地位。它將實(shí)時(shí)流處理、高效列式存儲、分布式計(jì)算和強(qiáng)大的索引能力融為一體,為需要快速洞察海量時(shí)序數(shù)據(jù)的應(yīng)用提供了一個(gè)強(qiáng)大、可擴(kuò)展且高可用的解決方案。無論是構(gòu)建實(shí)時(shí)業(yè)務(wù)儀表盤、進(jìn)行用戶行為分析,還是監(jiān)控復(fù)雜的基礎(chǔ)設(shè)施,Druid都是一個(gè)值得深入研究和采用的核心技術(shù)組件。
如若轉(zhuǎn)載,請注明出處:http://www.kazfg.cn/product/65.html
更新時(shí)間:2026-04-12 12:15:12